
Neste conteúdo, explicarei a como usar o Google Sheets para trazer dados úteis para suas campanhas de Google. Ou seja, para apoiar no planejamento web de conteúdo, SEO, dentre outros, reduzindo erros manuais e otimizando o tempo de execução — e o melhor, sem necessidade de saber codificar!
Com certa frequência, profissionais que trabalham no universo digital já se encontraram diante de uma situação em que é necessário extrair dados de um website.
Quando se está trabalhando em uma nova conta ou campanha, você pode não ter certas informações disponíveis para a criação de anúncios, por exemplo.
No mundo ideal, nós deveríamos receber todo conteúdo necessário: landing pages, descrições, urls e outros dados relevantes, e em um formato fácil de importar, como CSV, planilha de Excel ou Google Sheets. Ou pelo menos, ter acesso aos dados tabulados de forma que possam ser importados por meio de um dos formatos mencionados anteriormente.
Porém, sabemos que não é sempre assim que acontece na prática
Quando em meio a um cenário em que você não pode contar com ferramentas próprias para web scraping — e não possui conhecimento de código, como Python para auxiliar —, pode acabar tendo que executar uma tarefa maçante de copiar e colar manualmente centenas ou até milhares de dados.
Isso não só tende a levar a um resultado contraproducente, uma vez que pode resultar em erros, considerando que envolve uma pessoa manualmente navegando através de muitas páginas e itens e tendo que copiar e colar dados de um por um, como também pode significar muitas horas gastas em algo pouco estratégico e muito operacional. Em um contexto assim, certamente as chances de se cometer falhas são mais altas.
E após tudo isso, seria necessário ainda mais tempo para revisar o documento, objetivando garantir que realmente não há erros. E mesmo assim, claro que algo ainda pode escapar, afinal, somos humanos.
Desta forma, precisamos pensar em alternativas para se realizar este tipo de tarefa.
A boa notícia é que há algumas. Pretendo lhe apresentar uma maneira possível, que é através do IMPORTXML.
O que é o IMPORTXML?
Antes de iniciarmos, é necessário acessar o Google Sheets. Para acessá-lo, você pode fazê-lo através deste endereço: google.com/sheets/about/.
Caso sua atividade não esteja vinculada a uma empresa, selecione a opção “Ir para o Planilhas Google“.
Ao clicar neste botão, caso ainda não esteja, é preciso se logar em um conta Gmail, com e-mail e senha.
Observação: se você ainda não tem uma conta, sugiro fortemente que crie, será muito útil em seu dia-a-dia.
Após isso, recomendo que abra uma nova planilha em branco.
E finalmente chegamos no IMPORTXML. De acordo com o suporte do Google, a função IMPORTXML “importa dados de qualquer um dos vários tipos de dados estruturados incluindo XML, HTML, CSV, TSV, e RSS e ATOM XML feeds”.
Essencialmente, IMPORTXML é uma função que te permite extrair dados estruturados de websites, sem a necessidade de ter hard skills de codificação.
Por exemplo, é fácil e rápido extrair dados como títulos de páginas, descriptions, heading, links/urls, assim como algumas informações mais complexas.
Como o IMPORTXML pode ajudar a extrair elementos de uma página web?
A função em si é muito simples e requer somente dois valores:
- A URL da página web de origem que se tem a intenção de extrair ou copiar as informações;
- E o XPath do elemento em que o dado está contido.
XPath é um elemento padrão XSLT, que faz parte da recomendação W3C, e pode ser usado para navegar por meio de elementos e atributos em um documento XML. Ele é utilizado para identificar o local exato de qualquer elemento da página usando a estrutura do HTML DOM.
O XPath usa expressões de caminho para selecionar nós e configurações de nós em um documento XML. Essas expressões de caminho se parecem muito com caminhos utilizados pelos sistemas de computadores comuns, sendo que o XPath possui mais de 200 funções pré-prontas. Através dele, é possível capturar trechos de informação como Títulos de Páginas, Heading Tags, Descriptions de produtos em e-commerces, e qualquer outro elemento presente na página.
Existem funções para valores de strings, numéricos, booleanos, comparação de data e tempo, manipulações e outros. Atualmente, as expressões XPath também podem ser utilizados em JavaScript, Java, XML, PHP, Python, C, C++ e muitas outras linguagens.
Para exemplificar, irei utilizar a home-page do Portal E-Commerce Brasil. Portanto, o endereço-base será: https://www.ecommercebrasil.com.br/
Assim, iremos utilizar:
=IMPORTXML(“URL DA PÁGINA DE ORIGEM”; “CAMINHO XPATH”)
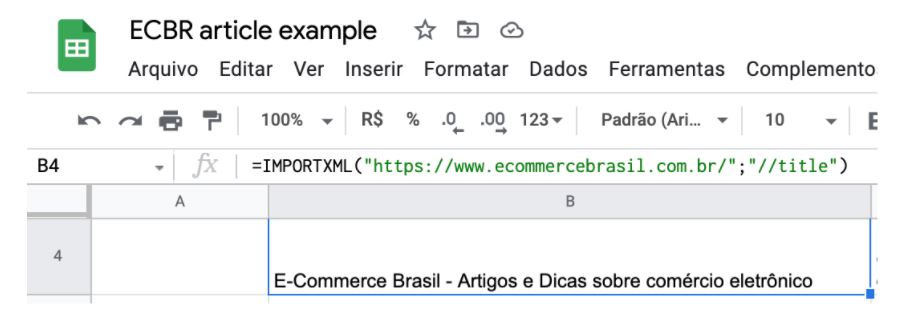
Então, para buscar o título do endereço da home-page do Portal E-Commerce Brasil, podemos fazer assim:
=IMPORTXML(“https://www.ecommercebrasil.com.br/“; “//title”)
O trecho “//title” é um caminho XPath.
O retorno desta função é: “E-Commerce Brasil – Artigos e Dicas sobre comércio eletrônico”.
Outro exemplo, para se buscar a “description” da página, podemos fazer da seguinte forma:
=IMPORTXML(“https://www.ecommercebrasil.com.br/“;”//meta[@name=’description’]/@content”)
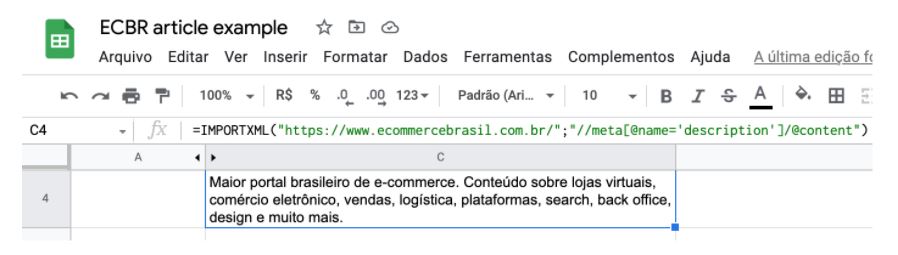
Sei que este último complicou um pouco mais, e para ajudá-lo a entender sua montagem, sugiro que acesse a documentação do XPath no site da w3shools.
Mas, basicamente, no exemplo acima, selecionamos todos os nós “meta” da documentação. Após, utilizamos os colchetes para buscar um predicado específico pertencente ao primeiro, e no caso, foi o conteúdo (selecionado pelo @), presente na meta name description.
Abaixo, apresento algumas das “queries” mais utilizadas e comuns no XPath:
- Título da Página: //title
- Meta description da Página: //meta[@name=’description’]/@content
- H1 da página: //h1
- Links da página: //@href
Vejamos o IMPORTXML em Ação
Profissionais de marketing e outros do meio digital, o IMPORTXML pode ser uma ótima saída para automação de muitas tarefas do cotidiano, de campanhas e criação de anúncios a pesquisas de conteúdo, e muito mais.
Claro, há muitos outros meios de se prover web scraping, principalmente para quem domina um pouco mais de codificação, mas essa é uma alternativa real e funcional, e que pode ir muito além com a utilização de fórmulas próprias do Google Sheets, por exemplo, e outros add-ons.
Continuando no cenário prático, por exemplo, poderia querer extrair de um jeito organizado, o bloco “Últimas notícias” do Portal E-Commerce Brasil, que será atualizado frequentemente.
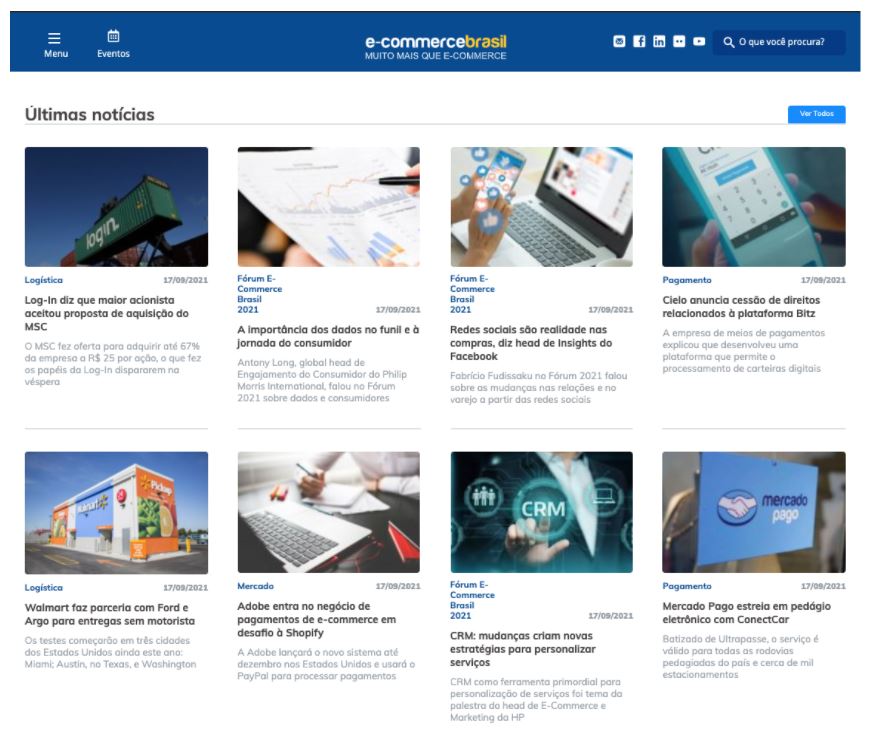
Para tanto, deve-se analisar minimamente a estrutura do website alvo. No caso do Ecommerce Brasil, para este bloco e montagem deste artigo, considerei mais objetivo apresentar o XPath específico para cada elemento.
Encontrando o XPath da página alvo
Para encontrar o XPath do item no qual queremos importar o conteúdo na planilha, irei utilizar o navegador Google Chrome.
O primeiro passo para isso, é identificar os elementos que deseja organizar. No exemplo que coloquei é necessário trazer a Categoria, o Título, a Chamada e a Data.
Para exemplificar, vou mostrar como identificar o XPath do Título. Para isso, basta clicar com o botão direito no mesmo, e na sequência, clicar em Inspecionar.
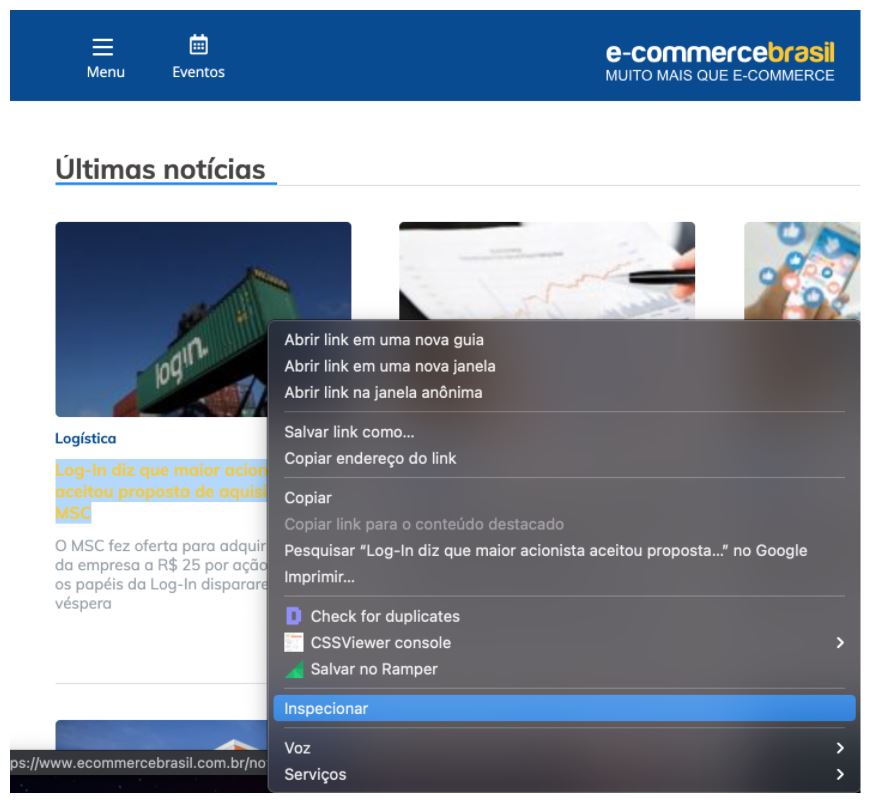
Após fazer isso, o Chrome Dev Tools do navegador Google Chrome irá abrir (famoso Inspetor). Confira se o elemento está corretamente selecionado – compare a marcação do Dev Tools com o que aparece identificado no próprio website. Caso esteja tudo certo, clique novamente com o botão direito no trecho marcado do próprio Dev Tools, na sequência, siga o caminho: COPY > COPY XPATH.
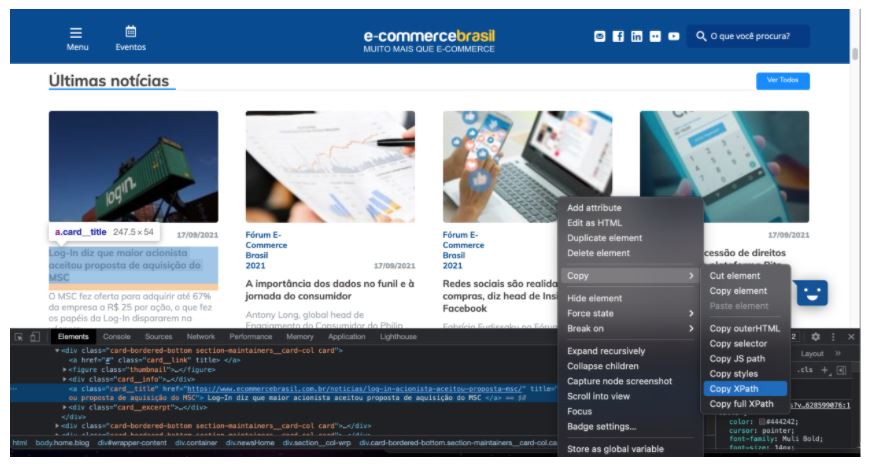
E pronto! Se você colar o que o navegador acabou de copiar em qualquer lugar, o resultado é um XPATH.
Neste caso, o resultado foi este:
//*[@id=”wrapper-content”]/div[4]/div[2]/div/div[1]/a[2]
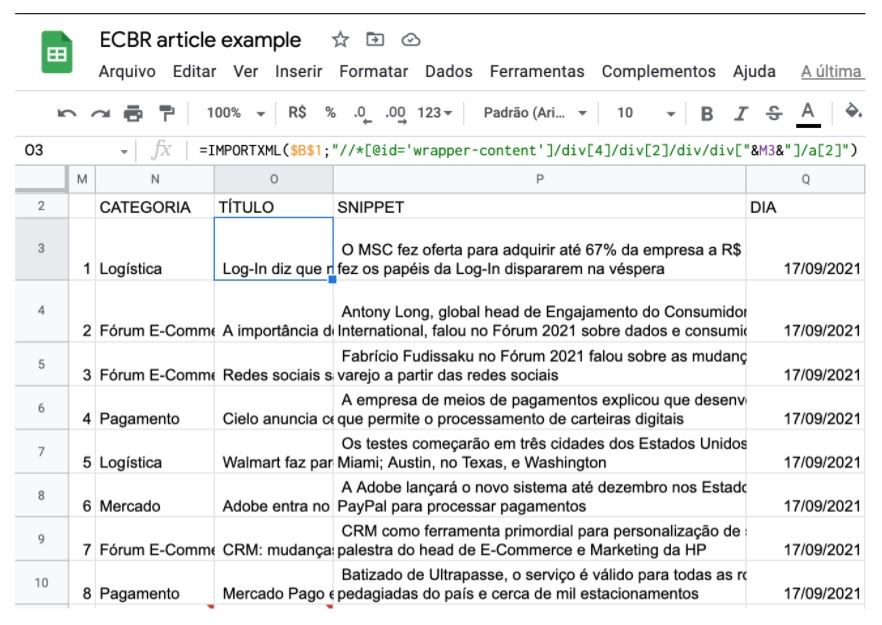
Para explicar como fiz, neste exemplo resolvi trazer elementos de predicados mais específicos. Por isso, há o uso de colchetes. Por um lado, isso é positivo para ser mais exato, por outro, é mais estático, quando se deseja deixar mais flexível é necessário estudar por algum tempo a estrutura do website alvo.
Uma vez seguindo o fluxo estático, pude notar que o bloco que se altera entre os títulos do “Últimas Notícias” é a última DIV, onde está o M3 no construtor de fórmulas, visível pelo print acima.
Para não ter que fazer manualmente todas as linhas – afinal, este é um de nossos objetivos -, na coluna M estabeleci índices com números de 1 até o 8, e utilizando de fórmula no Spreesheets, concatenei com o XPath.
Portanto, M3 significa /div[1], sendo que o número 1 vem justamente da coluna M linha 3. Assim, fiz com os demais títulos.
E, utilizando a mesma lógica, apliquei também para coletar Categoria, a Chamada (Snippet) e a Data (dia).
No final, as fórmulas ficaram assim:
- Categoria:
=IMPORTXML($B$1;”//*[@id=’wrapper-content’]/div[4]/div[2]/div/div[“&M3&”]/div[1]/span[1]/a”) - Título:
=IMPORTXML($B$1;”//*[@id=’wrapper-content’]/div[4]/div[2]/div/div[“&M3&”]/a[2]”) - Snippet (Chamada):
=IMPORTXML($B$1;”//*[@id=’wrapper-content’]/div[4]/div[2]/div/div[“&M3&”]/div[2]/text()”) - Dia (Data):
=IMPORTXML($B$1;”//*[@id=’wrapper-content’]/div[4]/div[2]/div/div[“&M3&”]/div[1]/span[2]/time”)
Observação: $B$1 é a coluna e linha no qual eu inseri o endereço-alvo, no caso, a URL da home-page do Portal Ecommerce Brasil – https://www.ecommercebrasil.com.br/.
Conclusão
Como você pode notar, através desta simples função do Google Sheets, consegui trazer os dados que gostaria, de forma bastante estruturada, evitando erros humanos e economizando muito tempo em momentos futuros.
Você pode aplicar essa técnica de scraping em qualquer trecho de informação que precisar para configurar uma campanha de anúncios no Google, Bing ou outro. Podemos incluir o endereço de URL das landing pages, o trecho de destaque de cada artigo, nome do autor do artigo, a data da publicação, as heading tags, títulos, dentre outros no seu documento do Google Sheets.
Para finalizar, deixarei outros exemplos adicionais:
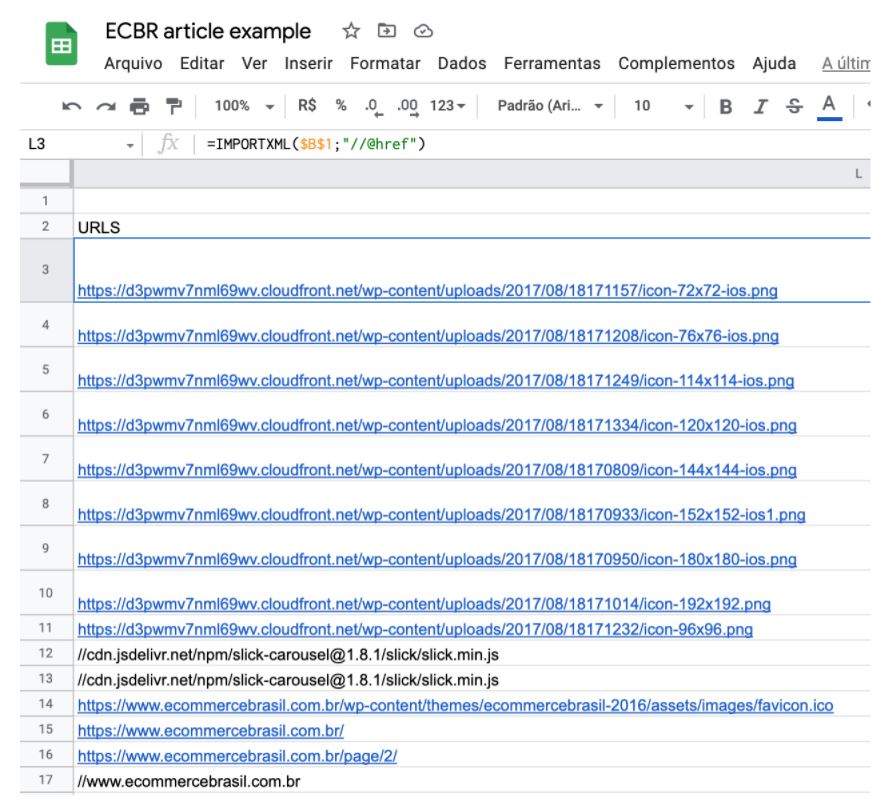
Para capturar todas as URLs do Portal E-commerce Brasil, você pode fazer com a seguinte fórmula:
=IMPORTXML($B$1;”//@href”)
Para trazer as Heading Tags, H2 e H3, pode fazer desta maneira:
=IMPORTXML($B$1;”//h2″)
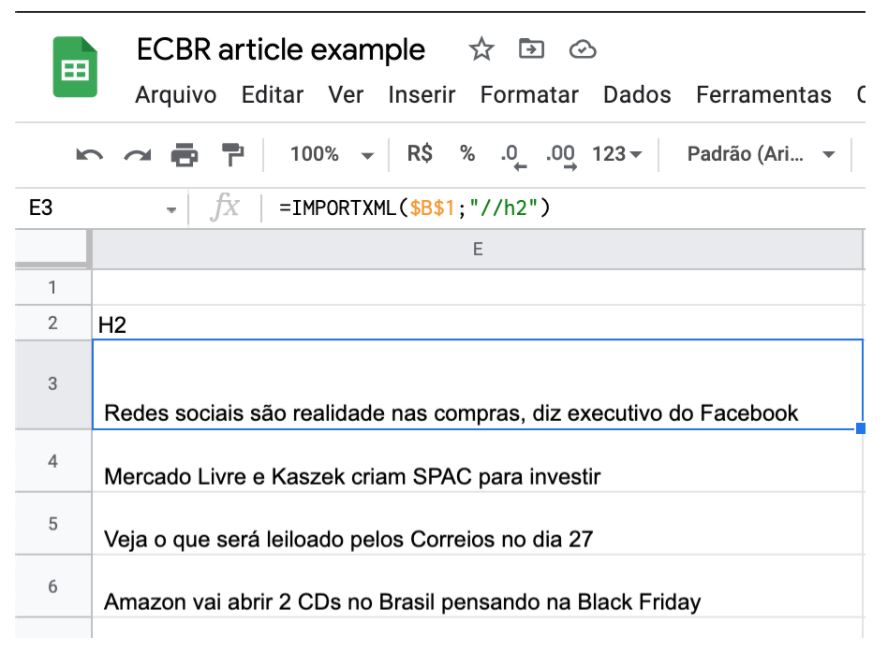
=IMPORTXML($B$1;”//h3″)

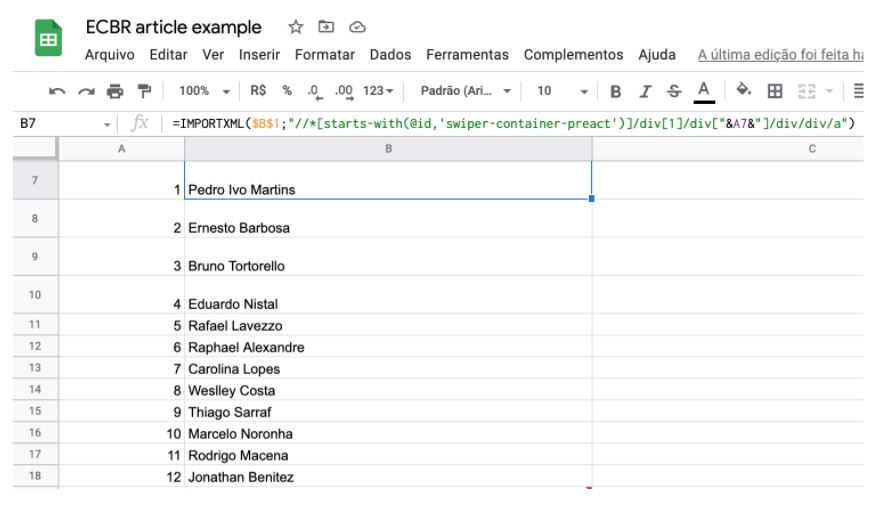
Para copiar os autores, execute a fórmula abaixo:
=IMPORTXML($B$1;”//*[starts-with(@id,’swiper-container-preact’)]/div[1]/div[“&A7&”]/div/div/a”)
A união do IMPORTXML no Google Sheets e o XPath pode ser bastante poderosa, sendo uma ótima ferramenta para tarefas relacionadas ao PPC (pay-per-click), assim como pode ser muito útil para diferentes projetos de web scraping, incluindo SEO e times voltados para conteúdo. Para a construção deste artigo utilizei como referência o conteúdo do Search Engine Journal, que me inspirou a apresentar um passo-a-passo bem “hands-on” à comunidade brasileira. Espero que tenha gostado e até o próximo artigo!
O post Web Scraping: como capturar dados por meio do Google Sheets apareceu primeiro em E-Commerce Brasil.
Na próxima semana farei mais um review com depoimento e resenha sobre Web Scraping: como capturar dados por meio do Google Sheets. Espero ter ajudado a esclarecer o que é, como usar, se funciona e se vale a pena mesmo. Se você tiver alguma dúvida ou quiser adicionar algum comentário deixe abaixo.
Nenhum comentário:
Postar um comentário